Be careful when interpreting your features importance in xgboost!
- Select a language for the TTS:
- UK English Female
- UK English Male
- US English Female
- US English Male
- Australian Female
- Australian Male
- Language selected: (auto detect) - EN
Play all audios:
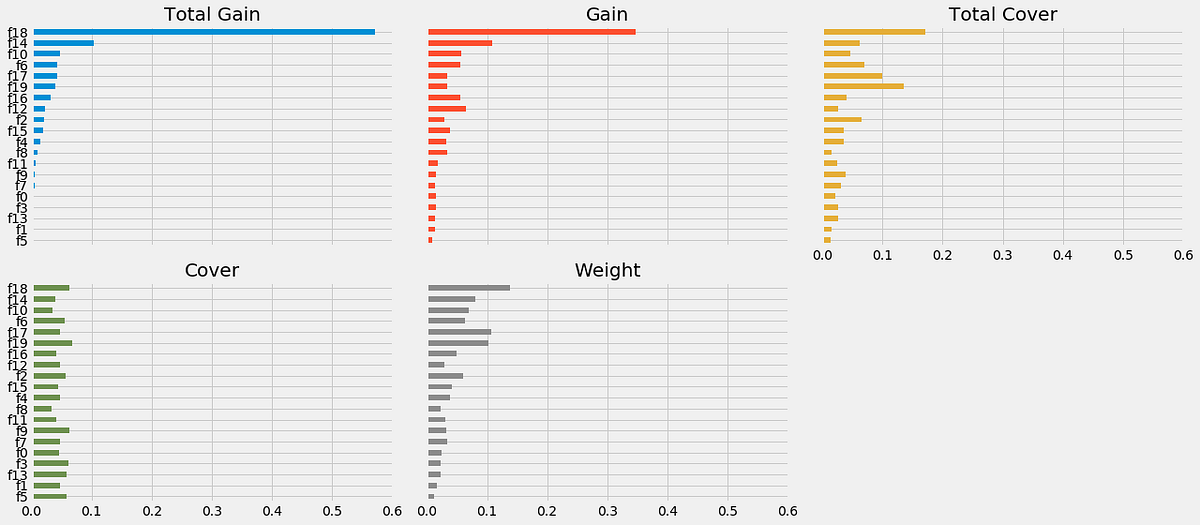
Be careful when interpreting your features importance in XGBoost, since the ‘feature importance’ results might be misleading! This post gives a quick example on why it is very important to
understand your data and do not use your feature importance results blindly, because the default ‘feature importance’ produced by XGBoost might not be what you are looking for. Assuming that
you’re fitting an _XGBoost for a _classification problem, an importance matrix will be produced. The importance matrix is actually a table with the first column including the names of all
the features actually used in the boosted trees, the other columns of the matrix are the resulting ‘importance’ values calculated with different importance metrics [3]: “The GAIN implies the
relative contribution of the corresponding feature to the model calculated by taking each feature’s contribution for each tree in the model. A higher value of this metric when compared to
another feature implies it is more important for generating a prediction. The COVERAGE metric means the relative number of observations related to this feature. For example, if you have 100
observations, 4 features and 3 trees, and suppose feature1 is used to decide the leaf node for 10, 5, and 2 observations in tree1, tree2 and tree3 respectively; then the metric will count
cover for this feature as 10+5+2 = 17 observations. This will be calculated for all the 4 features and the cover will be 17 expressed as a percentage for all features’ cover metrics. The
FREQUENCY (R)/WEIGHT (PYTHON) is the percentage representing the relative number of times a particular feature occurs in the trees of the model. In the above example, if feature1 occurred in
2 splits, 1 split and 3 splits in each of tree1, tree2 and tree3; then the weight for feature1 will be 2+1+3 = 6. The frequency for feature1 is calculated as its percentage weight over
weights of all features. _The Gain is the most relevant attribute to interpret the relative importance of each feature._ ‘GAIN’ is the improvement in accuracy brought by a feature to the
branches it is on. The idea is that before adding a new split on a feature X to the branch there was some wrongly classified elements, after adding the split on this feature, there are two
new branches, and each of these branch is more accurate (one branch saying if your observation is on this branch then it should be classified as 1, and the other branch saying the exact
opposite). ‘COVERAGE’ measures the relative quantity of observations concerned by a feature.”[3] WHY IS IT IMPORTANT TO UNDERSTAND YOUR FEATURE IMPORTANCE RESULTS? Suppose that you have a
binary feature, say gender, which is highly correlated with your target variable. Furthermore, you observed that the inclusion/ removal of this feature form your training set highly affects
the final results. If you investigate the importance given to such feature by different metrics, you might see some contradictions: Most likely, the variable _gender _has much smaller number
of possible values (often only two: male/female) compared to other predictors in your data. So this binary feature can be used at most once in each tree, while, let say, _age (with a higher
number of possible values) _might appear much more often on different levels of the trees. Therefore, such binary feature will get a very low importance based on the frequency/weight
metric, but a very high importance based on both the gain, and coverage metrics! A comparison between feature importance calculation in _scikit-learn_ Random Forest (or GradientBoosting) and
XGBoost is provided in [1]. Looking into the documentation of _scikit-lean _ensembles, the weight/frequency feature importance is not implemented. This might indicate that this type of
feature importance is less indicative of the predictive contribution of a feature for the whole model. So, before using the results coming out from the default features importance function,
which is the weight/frequency, take few minutes to think about it, and make sure it makes sense. If it doesn’t, maybe you should consider exploring other available metrics. Note: if you are
using python,you can access the different available metrics with a line of code: > #Available importance_types = [‘weight’, ‘gain’, > ‘cover’, ‘total_gain’, ‘total_cover’] > f =
‘gain’ > XGBClassifier.get_booster().get_score(importance_type= f) REFERENCES: EXPLAINING FEATURE IMPORTANCE BY EXAMPLE OF A RANDOM FOREST IN MANY (BUSINESS) CASES IT IS EQUALLY IMPORTANT
TO NOT ONLY HAVE AN ACCURATE, BUT ALSO AN INTERPRETABLE MODEL… towardsdatascience.com